บริการ Social listening หรือ Social Monitoring มีคนรู้จักหรือลูกค้าหลาย ๆ คนเคยสอบถามเข้ามาเขาถามว่าแล้ว ข้อมูลที่นำมาวิเคราะห์เขาเอาข้อมูล Data มาจากไหน แล้วหลักการทำงานของ Social Listening เขาทำงานกันอย่างไร? ซึ่งเอาประสบการณ์ที่เคยคลุกคลีกับ กลุ่ม Data Science, Data Engineer เลยเอามุมมองที่ได้ฟังมาเล่าต่อใน Blog ตัวเองแล้วกัน
การพูดถึงบนโลก Online เป็นจำนวนมาก ที่ Post ลงไปใน Social Network แต่ละ Platform มีจำนวน เป็นล้าน ๆ ๆ ข้อความต่อนาที เช่น Facebook มีการ Post ใน 60 วินาที มีข้อความที่พูดถึงบนโลก Online มากถึง 1.3 ล้านข้อความ

ข้อความเป็นจำนวนมากที่รวบรวม ของ Social network จะถูกรวบรวมกัน กลายเป็น Big Data ขนาดใหญ่ ซึ่ง Data ขนาดใหญ่นี้ส่วนใหญ่เป็น Data ที่ไม่มีโครงสร้างหรือเรียกว่า Unstructured Data ประกอบไปด้วย รูปภาพ , ข้อความ, เสียง , วีดีโอ หรือแม้กระทั้ง Sensor แล้ว เราจะเอาข้อมูลขนาดใหญ่แบบนี้เอามาวิเคราะห์ได้อย่างไร ?
ข้อมูล Data บนโลก Social Network ที่นำมาใช้งาน ในการนำข้อมูลเข้ามา มีด้วยกัน 2 แบบเป็นที่นิยมกัน
- API (Application Programing Interface) เป็นการยินยอมของเจ้าของ Platform ผู้ให้บริการ Social Network เช่น Facebook , Twitter , IG , You tube ซึ่งผู้ให้บริการแต่ละ Platform จะมี API ที่ไว้สำหรับการต่อเชื่อมของ 3rd Party โดยจะมีการตกลงค่าใช้จ่ายบริการระหว่างกัน ข้อมูลนี้อาจจะไม่จำเป็นต้องเก็บเข้าถัง Data Lake โดยตรง (แต่บางครั้งการเก็บเข้า Data Lake) จะทำให้การดึงข้อมูลทำได้เร็วขึ้น

2. Web Scraping การใช้ Script การดึง Data เพื่อเก็บ Contents ในแต่ละ Page ส่วนใหญ่ที่ใช้ Program ในการดึงข้อมูลกัน จะใช้ Python หรือ Serenium Python โดยจะเก็บไว้ที่ Data Lake (รวมข้อมูลขนาดใหญ่)

ลองอ่าน การดึง Data จาก Serenium ได้บางส่วนที่หามา https://medium.com/@KaeroiData/web-scraping-%E0%B8%94%E0%B9%89%E0%B8%A7%E0%B8%A2-python-%E0%B9%82%E0%B8%94%E0%B8%A2-selenium-beginner-ad6369624ccd
เมื่อได้ Data โดยการต่อ API หรือ มาจาก Data Lake ที่เก็บข้อมูลแล้ว ข้อมูลจะถูกดึงขึ้นมาวิเคราะห์ โดยการใช้ Keywords , #hashtag แล้วนำมาแสดงผลตามแต่ละ Dash Board ของผู้ให้บริการแต่ละเจ้าที่แสดงจุดเด่นของตัวเองขึ้นมา

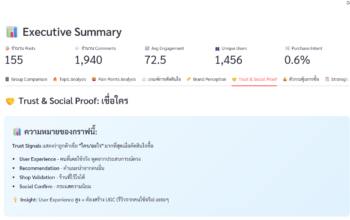
Dashboard ของการแสดงผลแล้วแต่การใช้งานของ Social Listening / Social Monitoring
Data Science เป็นองค์ประกอบสำคัญในการนำ Data มาจัดหมวดหมู่ แล้วทำให้การวิเคราะห์ข้อมูลเพื่อหา Insight ได้ง่ายขึ้น ซึ่งขึ้นอยู่กับว่า เราต้องการเอา Model อะไรให้กับ Dashboard ในการแสดงผลแล้วนำไปใช้งาน ซึ่ง คร่าว ๆ ที่จะต้องเห็นของทุก Platform คือ Word cloud / Sentiment

Word Cloud คืออะไร ข้อความที่มีการพูดถึงแล้วรวบรวมออกมาแล้วมีการตัดคำกัน แล้วมานับทีหลังว่ามีคำอะไรที่มีการพูดถึงมากที่สุด

ลองดูตัวอย่างการสร้าง Word Cloud ง่าย ๆ ที่เคยเขียนไว้ใน blog นี้ https://onlinemedia.idea2mobile.com/?p=3492 สร้าง Word Cloud จากลูกค้าถามอะไรเรามาบ้างใน Inbox facebook

Sentiment การวัดระดับความรู้สึกของทาง Content จะมีด้วยกัน 3 อย่าง
- Positive คือข้อความที่มีผลต่อความรู้สึกเชิงบวก
- Negative คือ ข้อความที่มีผลต่อความรู้สึกเชิงลบ
- Neutral คือ ข้อความที่มีผลต่อความรู้สึกเป็นกลาง
สำหรับ Sentiment เคยทำ Data ต้นทาง จำนวน นึง แล้ว ใช้ความ Machine Learning ให้เข้าไปเรียนรู้ว่า ถ้ามีข้อความใหม่ ๆ เข้ามาให้จับดูว่า ข้อความดังกล่าวจะตกอยู่ใน 3 อันดับแบบไหน แล้ว ปลายทางคือการวัด Accuracy ว่าได้ผลจำนวนกีเปอร์เซ็นต์
สามารถอ่าน Blog เกี่ยวกับการทำ Sentiment ได้จำนวนมาก เช่น วิเคราะห์ความรู้สึกด้วย sentiment analysis Click
สำหรับตัวคนเขียนปัจจุบัน ร่วมงานกับทาง Mandala Social Listening เลย สามารถแจ้งได้เลยว่า Data Social listening ที่ใช้งานอยู่ของ Mandala ซี่งเป็น Platform ที่ต่อเชื่อมข้อมูลที่ถูกต้องจาก Facebook / Twitter / IG / Pantip อย่างถูกต้องไม่มีการ Scaping Data ที่ผิดกฏแต่อย่างใด
ทั้งหมดนี้คือการบอกเล่ามุมมองประสบการณ์ที่ได้คลุกคลีกับ Data Science, Data Engineer เลยเอามุมมองมาเล่าสู่กันฟัง
Webmaster
Anantachai ittiworapong